-
[Mysql] MySQL NDB ClusterMySQL_Section/cluster 2014. 11. 18. 17:23
MySQL Cluster
저작권:이 문서는 자유롭게 배포가 가능합니다. 단 상업적 용도로 사용할 수 없습니다.
배포 시 작성자의 이름 및 출처를 꼭 명시하기 바랍니다.
작성자 : f405(ccotti22)작성일 : 2005년 8월 10일 수요일
이메일 : f405@naver.com
이 문서는 MySQL Cluster 매뉴얼을 번역, 정리한 것으로 틀린 부분을 다소 포함할 수 있으며, 저는그에 대한 책임을 지지 않겠습니다.부족하지만 다른 분들도 공부하는데 도움이 되길 바랍니다.
그리고 이 문서를 작성하기 전 참고한 리눅스 및 MySQL 문서들을 작성하신 많은 선배님들에게감사의 말씀을 드립니다.
그리고 이 후부터는 경어는 생략하였습니다. 양해의 말씀을...MySQL 클러스터는 분산 컴퓨팅 환경에서 high-availability와 high-redundancy를 채택하였다. MySQL 클러스터는 NDB 클러스터 스토리지 엔진을 사용하여, 클러스터에서 여러 개의 서버가 함께 돌아가도록 한다. MySQL 클러스터가 지원하는 운영 체제는 Linux, Mac OS X, Solaris 등 이다. 더 자세한 정보는 다음 사이트를 참고 하길 바란다.
http://www.mysql.com/products/cluster
1. 1. MySQL Cluster Overview
MySQL 클러스터는 share-nothing 시스템에서 in-memory 데이터 베이스의 클러스터링을 가능하게 한다. 이러한 아키텍쳐는 특정한 하드웨어 및 소프트웨어를 요구하지 않으므로 비용을 절감할 수 있도록 하며, 각 콤포넌트가 고유 메모리와 디스크를 보유함으로 단일 취약점(single point of failure)을 가지지 않는다.
MySQL 클러스터는 일반 MySQL 서버에 NDB라는 스토리지 엔진을 통합하여, 다음 그림과 같이MySQL서버, NDB 클러스터의 데이터 노드, MGM 서버가 포함된 컴퓨터와 데이터에 접근하기위한 어플리케이션 프로그램으로 구성된다.
데이터가 NDB 클러스터 스토리지 엔진에 저장될 때, 테이블은 데이터 노드에 저장된다. 각 테이블은 클러스터의 MySQL 서버에서 직접 접근이 가능하다. 그래서 클러스터의 어떤 정보를 업데이트 하면, 다른 모든 MySQL서버에서 곧바로 확인할 수 있다.
MySQL 클러스터의 데이터 노드에 저장된 데이터는 미러링이 가능하며, 클러스터는 트랜잭션 중단 등 각 노드들의 상태에 대한 핸들링이 가능하다.
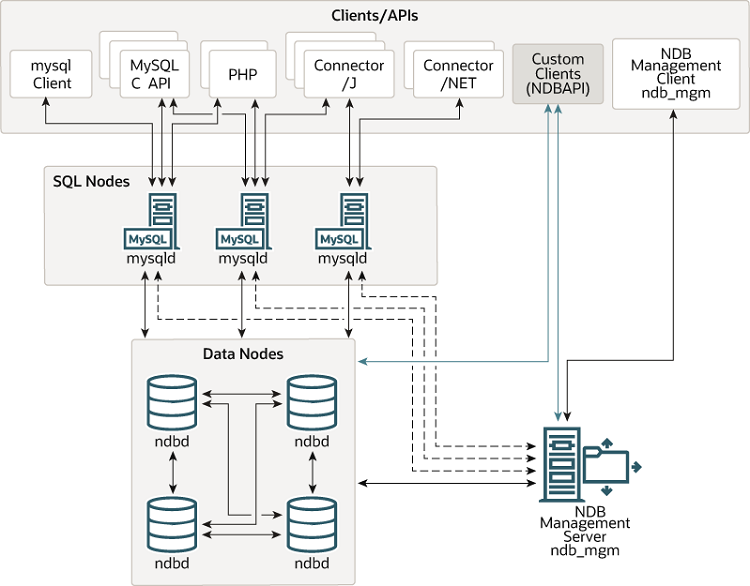
MySQL 클러스터의 구성
( 참조 : http://dev.mysql.com/doc/mysql/en/mysql-cluster-overview.html )
2. 2. Basic MySQL Cluster Concepts
NDB는 높은 가용성과 데이터 지속성을 갖는 인 메모리 스토리지 엔진이다. DB 스토리지 는failover와 로드 밸런싱 옵션을 설정할 수 있다.
MySQL 클러스터는 NDB 스토리지 엔진과 MySQL 서버로 구성되어 있으며, MySQL 클러스터의 클러스터 부분은 MySQL 서버에 독립적이다. MySQL 클러스터의 각 부분은 노드로 간주한다.
"노드"는 일반적으로 컴퓨터를 지칭하지만 MySQL 클러스터에서는 "프로세스"를 말한다.
클러스터 노드에는 세 가지 타입이 있으며, MySQL Cluster를 구성하기 위해 최소한 노드 세 개가 있어야 한다.
l MGM node : 이 노드는 설정을 포함, 다른 노드를 관리하는 매니저 노드이다.
다른 노드보다 가장 먼저 실행되며 ndb_mgmd 명령으로 실행시킨다.
l data node : 클러스터의 데이터를 저장하는 노드이다.
ndbd 명령으로 실행시킨다.
l SQL node : 클러스터 데이터에 접근하는 노드이다.
MySQL 클러스터에서는 NDB 클러스터 스토리지 엔진을 사용하는 MySQL 서버가 클라이언트 노드이다.
mysqld --ndbcluster나 mysqld 명령으로 실행시키는데, 이 때는 my.cnf 에ndbcluster를 추가한다.MGM 노드는 클러스터 컨피그레이션 파일과 로그를 관리한다. 데이터 노드에 이벤트가 발생하면, 데이터 노드는 그에 대한 정보를 매니저 서버로 보내고, 매니저 서버는 클러스터 로그를 기록한다.
Simple Multi-Computer How-To
다음과 같이 4대의 컴퓨터로 클러스터를 구성하는 것을 가정하고 있다.
(4개의 노드로 구성되고, 각각의 노드는 편이성을 위해 IP로 지칭한다.)
아래에서 필요한 컴퓨터는 리눅스가 설치된 인텔 기반 데스크탑 PC이며, 4대 모두 동일한 이더넷 카드(100Mbps나 1기가 비트)가 필요하다.Node
IP Address
Management (MGM) node
192.168.0.10
MySQL server (SQL) node
192.168.0.20
Data (NDBD) node "A"
192.168.0.30
Data (NDBD) node "B"
192.168.0.40

설치 및 사용 시 주의할 점은 MySQL 클러스터는 클러스터 노드 간 커뮤니케이션에 암호화 및 보호 장치가 전혀 없으므로, 웹 상에서 사용하려면 방화벽을 사용하는 등의 보안상의 대책이 필요하다는 것이다.
MySQL Cluster를 사용하기 위해서는 -max 버전을 설치해야 한다.
모든 설치는 root권한으로 진행하며 작업에 필요한 파일은 /usr/local/ 에 저장한다.1. /etc/passwd 와 /etc/group 파일에서 mysql그룹과 유저가 있는지 확인한 후없으면 다음과 같이 생성한다.
# cd /usr/local
# groupadd mysql
# useradd -g mysql mysql2. 유저와 그룹 생성 후 압축을 풀고, 심볼릭 링크를 걸어준다.
# tar -xzvf mysql-max-4.1.13-pc-linux-gnu-i686.tar.gz
# ln –s /usr/local/mysql-max-4.1.13-pc-linux-gnu-i686 mysql3. mysql 디렉토리로 이동하여 시스템 데이터베이스 생성을 위한 스크립트를 실행시킨다.
# cd mysql
# scripts/mysql_install_db --user=mysql4. MySQL 서버와 데이터 디렉토리의 퍼미션을 설정한다.
# chown -R root .
# chown -R mysql data
# chgrp -R mysql .
5. 시스템 부팅 시 자동적으로 Mysql을 실행할 수 있도록 설정한다.
# cp support-files/mysql.server /etc/rc.d/init.d/
# chmod +x /etc/rc.d/init.d/mysql.server
# chkconfig --add mysql.server6.MGM (management) 노드를 별도의 PC에 설치할 경우 mysql 데몬은 설치하지 않아도 무방하다. 위와 같이 설치한 후 MGM 서버는 다음과 같이 설치를 계속한다.# cd /usr/local/mysql/bin/
# cp ndb_mgm* /usr/local/bin/
# chmod +x ndb_mgm*7. 각 데이터 노드와 SQL 노드는 MySQL서버 옵션과 connectstring에 대한 정보가 포함된
my.cnf파일이 필요하고, MGM노드는config.ini파일이필요하다.에디터를열어다음과같이편집한후파일을저장한다.# vi /etc/my.cnf[MYSQLD] # Options for mysqld process:
Ndbcluster # run NDB engine
ndb-connectstring=192.168.0.10 # location of MGM node
[MYSQL_CLUSTER] # Options for ndbd process:
ndb-connectstring=192.168.0.10 # location of MGM node
8. MGM 노드의 설정 파일을 만들기 위해 적당한 디렉토리를 만든 후 에디터를 열어
다음과 같이 편집한다.
# mkdir /var/lib/mysql-cluster
# cd /var/lib/mysql-cluster
# vi config.ini
[NDBD DEFAULT] # Options affecting ndbd processes on all data nodes:
NoOfReplicas=2 # Number of replicas
DataMemory=80M # How much memory to allocate for data storage
IndexMemory=52M # How much memory to allocate for index storage
# For DataMemory and IndexMemory, we have used the
# default values. Since the "world" database takes up
# only about 500KB, this should be more than enough for
# this example Cluster setup.
[TCP DEFAULT] # TCP/IP options:
portnumber=2202 # This the default; however, you can use any
# port that is free for all the hosts in cluster
# Note: It is recommended beginning with MySQL 5.0 that
# you do not specify the portnumber at all and simply
# allow the default value to be used instead
[NDB_MGMD] # Management process options:
hostname=192.168.0.10 # Hostname or IP address of MGM node
datadir=/var/lib/mysql-cluster # Directory for MGM node logfiles[NDBD] # Options for data node "A":
# (one [NDBD] section per data node)
hostname=192.168.0.30 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for this data node's
# datafiles
[NDBD] # Options for data node "B":
hostname=192.168.0.40 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for this data node's
# datafiles
[MYSQLD] # SQL node options:
hostname=192.168.0.20 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for SQL node's datafiles
# (additional mysqld connections can be
# specified for this node for various
# purposes such as running ndb_restore)
설치와 설정 과정이 끝났다. 이제 실행을 해 보자.클러스터 노드들은 각각 실행되어야 한다.
실행 순서는 매니지먼트 노드를 가장 먼저 실행할 것을 권한다.
그 다음은 스토리지 노드와 SQL노드 순이다.1. 매니지먼트 호스트에서 MGM 노드 프로세스를 실행시켜 보자.
컨피그레이션 파일을 찾을 수 있도록 –f 옵션을 주도록 한다.
# ndb_mgmd -f /var/lib/mysql-cluster/config.iniMGM 노드를 다운시킬 때에는 다음과 같이 하면 된다.
# ndb_mgm –e shutdown2. 다음으로 데이터 노드 호스트에서 NDBD프로세스를 실행시킨다.
--initial이란옵션는ndbd를처음실행할때와컨피그레이션이바뀐후재시작할때만사용한다.# ndbd –initial3. SQL 노드는 다음과 같이 mysql.server를 실행시킨다.
# /etc/rc.d/init.d/mysql.server start4. 이제 모든 노드가 실행되었으니 MGM 노드 클라이언트를 띄워 간단히 테스트를 해보자.
Ndb_mgm명령어를 입력하였을 때 정상적으로 동작하는 모습은
다음과 같이 프롬프트가 떨어지는 모습이다.# ndb_mgm
-- NDB Cluster -- Management Client --
ndb_mgm>5. 이제 show명령어를 사용하여 클러스터의 모든 노드들이 정상적으로 연동되는지 확인을 해 보자.
HELP 를 입력하면 다른 명령어들도 확인해 볼 수 있다.
다음과 같이 4개의 노드를 구성하는 것에 성공하였다.ndb_mgm> show
Connected to Management Server at: 192.168.0.10:1186
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=2 @192.168.0.30 (Version: 4.1.13, Nodegroup: 0, Master)
id=3 @192.168.0.40 (Version: 4.1.13, Nodegroup: 0)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @192.168.0.10 (Version: 4.1.13)
[mysqld(API)] 1 node(s)
id=4 (Version: 4.1.13)
ndb_mgm>
3. MySQL 클러스터의 제한
MySQL Cluster 4.1.x 버전은 다음과 같은 사용상의 제한점을 지닌다.l 트랙잭션 수행 중의 롤백을 지원하지 않으므로, 작업 수행 중에 문제가 발생하였다면,
전체 트랙잭션 이전으로 롤백하여야 한다.
l 실제 논리적인 메모리의 한계는 없으므로 물리적으로 허용하는 만큼 메모리를 설정하는 것이가능하다.
l 컬럼 명의 길이는 31자, 데이터베이스와 테이블 명은 122자까지 길이가 제한된다.
l 데이터베이스 테이블, 시스템 테이블, BLOB인덱스를 포함한 메타 데이터(속성정보)는 1600개까지만 가능하다.
l 클러스터에서 생성할 수 있는 테이블 수는 최대 128개이다.
l 하나의 로우 전체 크기가 8KB가 최대이다(BLOB를 포함하지 않은 경우).
l 테이블의 Key는 32개가 최대이다.
l 모든 클러스터의 기종은 동일해야 한다. 기종에 따른 비트저장방식이 다른 경우에 문제가 발생하기 때문이다.
l 운영 중 스키마 변경이 불가능하다.
l 운영 중 노드를 추가하거나 삭제할 수 없다.
l 최대 데이터 노드의 수는 48개이다.
l 모든 노드는 63개가 최대이다. (SQL node, Data node, 매니저를 포함)
4. 4. MySQL Cluster FAQ
Cluster 와 Replication의 차이
리플리케이션은 비동기화 방식이고, 클러스터는 동기화 방식이다.
따라서 리플리케이션은 일방적으로 데이타를 전달하여 복제를 하지만 클러스터는 동기방식이므로 데이타를 복제한 후 결과를 확인하기 때문에 데이타 누락이 발생하지 않는다.
다만 복제한 결과를 확인해야 하기 때문에 Cluster가 Replication보다는 속도가 느리다.
또한 Replication의 경우 복제된 데이터에 대한 신뢰를 할 수 없다.
Cluster가 사용하는 네트워크 (How do computers in a cluster communicate?)
MySQL 클러스터는 TCP/IP를 통해 서로 통신한다. 최소한 100Mbps의 이더넷을 사용해야 하며원활한 통신을 위해 gigabit 이더넷을 권고한다.
실제 데이터가 메모리에 존재하여 사용되며 물리적인 측면에서 봤을 때 CPU, 메모리, 각 노드간의 통신을 위한 네트워킹이 주를 이룬다. 이중 가장 속도가 느린 네트워크의 속도를 높임으로써 전체적인 빠른 동작이 가능하도록 해야 한다.
또한, 더욱 빠른 SCI 프로토콜도 지원하며, 이는 특정 하드웨어를 필요로 한다.
클러스터를 구성하기 위해 컴퓨터가 얼마나 필요한가?
최소한 3대가 있어야 클러스터 구성이 가능하나, MGM 노드와 SQL 노드, 스토리지 노드 둘, 이렇게 4 대로 구성하길 권한다. 하나의 노드가 실패했을 때 지속적인 서비스를 하기 위해서 MGM노드는 분리된 컴퓨터에서 실행되어야 한다.
클러스터에서 각 컴퓨터들이 하는 일은?
MySQL 클러스터는 물리적, 논리적으로 구성된다. 컴퓨터는 물리적 요소이며 호스트라고 불리기도 한다. 논리적, 기능적 요소는 노드이다. 노드는 역할에 따라 MGM 노드, data 노드(ndbd), SQL 노드로 나뉜다.
어떤 OS에서 사용할 수 있는가?
MySQL 4.1.12 현재 MySQL 클러스터는 공식적으로 Linux, Mac OS X, Solaris를 지원한다.
MySQL 클러스터가 요구하는 하드웨어 사양은?
NDB가 설치되고 실행되는 모든 플랫폼이면 가능하나, 당연히 빠른 CPU, 높은 메모리에서 더 성능이 좋다(64-bit CPU에서 더 빠르다). 네트워크은 일반 TCP/IP를 지원하면 되고, SCI 를 지원하려면 특정 하드웨어가 요구된다.
MySQL 클러스터가 TCP/IP를 이용한다면 하나 이상의 노드를 인터넷을 통해 다른 곳에서 실행시킬 수 있는가?
가능하다. 하지만 MySQL 클러스터는 어떠한 보안도 제공되지 않으므로, 외부에서 클러스터 데이터 노드나 매니저 노드에 직접 접근하지 못하도록 해야 한다.
클러스터 사용을 위해 새로운 프로그래밍 언어나 쿼리를 배워야 하나?
표준 (My)SQL 쿼리나 명령을 사용하므로 그러지 않아도 된다.
클러스터 사용 시 에러나 경고 메시지는 어디서 찾나 ?
두 가지 방법이 있다.
MySQL창에서 SHOW ERRORS나 SHOW WARNINGS로 확인하는 방법과 프롬프트 상태에서perror --ndb error-code 를 사용하는 방법이 있다.
MySQL Cluster transaction-safe? 어떤 테이블 타입이 클러스터를 지원하나?
MySQL에서 NDB 스토리지 엔진과 생성된 테이블은 트랜잭션을 지원한다. NDB는 클러스터링만지원하는 MySQL 스토리지 엔진이다.
"NDB" 의 의미는?
"Network Database".
클러스터를 지원하는 MySQL 버전은? 소스를 컴파일 해야 하나?
MySQL-max 4.1.3부터 지원한다. 바이너리 파일은 컴파일을 할 필요가 없다.
RAM은 얼마나 필요한가? 디스크는 사용하지 못하나?
클러스터는 오직 in-memory이며, 모든 테이블 데이터(인덱스 포함)가 RAM에 저장된다. 클러스터에서 필요한 RAM용량은 다음 공식으로 계산한다.
(SizeofDatabase * NumberOfReplicas * 1.1 ) / NumberOfDataNodes
ERROR 1114: The table 'my_cluster_table' is full
위와 같은 에러가 발생했을 때는 할당된 메모리가 부족한 경우이다.
FULL TEXT 인덱스를 지원하는가?
현재 지원하지 않는다.
하나의 컴퓨터에서 여러 개의 노드가 돌아가는가?
가능하긴 하지만 권하진 않는다. 각 노드들이 다른 컴퓨터에서 실행되는 것이 더 안정적이다.
클러스터를 재시작하지 않고 노드를 추가할 수 있는가?
할 수 없다. MGM 이나 SQL 노드를 추가하려면 새로 시작해야 한다.
어떻게 기존의 MySQL 데이터베이스를 클러스터로 임포트 하는가?
ENGINE=NDB 나 ENGINE=NDBCLUSTER 옵션을 가진 테이블은 임포트할 수 있다.
또는 ALTER 기능으로 기존의 테이블을 클러스터로 변환 사용할 수 있다.
- ALTER TABLE OLD_TABLE ENGINE=NDBCLUSTER;
Arbitrator란 ?
클러스터에서 한 개 혹은 그 이상의 노드가 실패할 경우, MGM 서버나 다른 노드가 그 노드의 역할을 대신하여 다른 노드들로 하여금 실패한 노드와 같은 노드로 인식하게 하는 기능을 한다. 이것을 중재인이라고 한다.
클러스터 shut down시에 어떤 일이 일어나느가?
클러스터 데이터 노드의 메모리에 있던 데이터가 디스크에 쓰여지고, 그 다음에 클러스터가 시작될 때 다시 메모리에 로드된다.
클러스터에서 다른 매니저 노드를 구성하는 것은?
fail-safe에 있어서 도움이 된다. 단지 하나의 MGM 노드 만이 클러스터를 컨트롤 할 수 있지만MGM 노드 하나를 primary로, 추가의 매니저 노드를 primary MGM 노드가 실패했을 때 인계받도록 하면 된다.
5. 5. MySQL Cluster Glossary
Cluster
일반적으로 Cluster는 하나의 업무를 수행하기 위해 함께 동작하는 컴퓨터 세트이다.
NDB Cluster는 자료저장, 복구, 컴퓨터 간의 분배 관리 등을 시행하기 위해 MySQL을 사용하는Storge Engine 이다. MySQL Cluster는 in-memory storage를 사용한 shared-noting 아키텍쳐에서 분산된 MySQL DB를 지원하기 위해 NDB엔진을 사용하여 함께 돌아가는 컴퓨터 그룹이다.
Configuration Files
클러스터, 호스트, 노드에 관계된 직접적인 정보를 포함하는 파일이다.
클러스터 시작 시 Cluster의 MGM 노드가 읽어들인다.
Backup
디스크나 다른 Long-term Storage에 저장되는 모든 클러스터 데이타, 트랜젝션, 로그의 완전한 카피를 말한다.
Restore
백업에 저장되는 것과 같이 클러스터에 그 전 상태로 되돌리는 것을 말한다.
CheckPoint
일반적으로 데이타가 디스크에 저장될 때 체크포인트에 도달한다고 말한다.
클러스터에서는 Committed된 트랜잭션을 디스크에 저장하는 시간을 말한다.
NDB Storage Engine에는 일관되게 클러스터의 데이타를 보존하기 위해 두 종류의CheckPoint가 있다.
LocalCheckPoint(LCP) : 싱글 노드의 체크포인트. 그러나 클러스터의 모든 노드에서 LCP를 사용한다. LCP는 디스크에 노드의 모든 데이타를 저장하도록 한다(보통 매 몇 분마다).클러스터 Activity의 노드와 레벨, 다른 요인에 의해 저장되는 데이타의 양은 의존적이다.
GlobalCheckPoint(GCP) : GCP는 모든 노드의 트랜잭션이 동기화되고, redo-log가 Disk에 저장될 때 몇 분마다 발생한다.
Cluster Host
MySQL Cluster의 구성 컴퓨터. 클러스터는 물리적 구조와 논리적 구조를 가진다.
물리적으로 클러스터는 Cluster Host라는 컴퓨터의 수로 구성된다.
Node
MySQL Cluster의 논리적, 기능적 요소를 말하며 Cluster Node라고도 한다.
MySQL Cluster에서는 node란 용어를 Cluster의 물리적 Component인 Process를 지칭한다. MySQL Cluster가 동작하기 위해 3가지 타입의 노드가 있다.
MGM node
- MySQL Cluster에서 다른 노드들의 설정 정보, 노드의 시작과 정지, 네트워크 파티셔닝, 백업과 저장 등을 포함하여 다른 노드들을 관리한다.
SQL node (MySQL Server)
- 클러스터의 데이터 노드안에 저장된 데이터를 Serve 하는 MySQL Server 인스턴스.
데이타를 저장, 분배, 업데이트하는 클라이언트는 MySQL Server를 통해 접근 가능하다.
Data node
- 이 노드는 실제 데이타를 저장한다.
현재 싱글 클러스터는 총 48개의 데이타 노드를 지원한다.
싱글 머신에 한 개 이상의 노드가 공존할 수도 있고, 한 머신에 완전한 클러스터를 구성하는 것도가능하다. MySQL 클러스터에서 호스트는 클러스터의 물리적 컴퍼넌트이며, 노드는 논리적 혹은기능적인 컴퍼넌트, 즉 프로세스라는 것을 잊지 말자.
Node group
데이터 노드의 집합. 노드 그룹 안의 모든 데이터 노드는 같은 데이터(fragment)를 포함한다. 그리고 싱글 그룹의 모든 노드는 다른 호스트에 존재해야 한다.
Node failure
MySQL 클러스터는 클러스터를 구성하는 어느 한 노드의 기능에만 의존적이지 않다. 클러스터는하나 혹은 몇 개의 노드가 실패해도 계속될 수 있다.
Node restart
실패한 클러스터 노드의 리스타팅 과정.
Initial node restart
노드의 이전의 파일 시스템을 지우고 시작하는 클러스터 노드의 과정. 소프트웨어 향상과 그 밖의 특별한 상황 등에 사용된다.
System crash(or System fail)
클러스터의 상태가 확인되지 않는 등 많은 클러스터 노드가 실패했을 때 일어날 수 있다.
System restart
클러스터의 리스타팅과 디스크 로그 및 체크 포인트로부터 reinstall하는 프로세스를 말한다. 클러스터를 shutdown 한 이후에 일어나는 과정이다.
fragment
데이터베이스 테이블의 한 부분. NDB스토리지 엔진에서 테이블을 나누어 fragments의 수에 따라 저장한다. Fragment는 파티션이라 불리기도 한다. MySQL 클러스터에서 테이블은, 머신과노드 간의 로드 밸런싱을 용이하게 할 수 있도록 fragment된다.
Replica
NBD 스토리지 엔진에서 각 테이블 프레그먼트는 여분을 포함하여 다른 데이터 노드에 저장된많은 replica를 갖는다. 현재는 fragment 당 4개 이상의 replica가 가능하다.
Transpoter
노드들 간의 데이터 이동을 제공하는 프로토콜
TCP/IP(local), TCP/IP(remote), SCI, SHM(MySQL 4.1 버전에서 실험적임)
NDB(Network DataBase)
NDB는 MySQL클러스터에서 사용하는 스토리지 엔진을 말 함.
NDB 스토리지 엔진은 모든 일반적인 MySQL 컬럼 타입과 SQL문을 지원하며, ACID(DB무결성보장을 위한 트랜잭션)성질을 가진다.
Shared-nothing architecture
MySQL 클러스터의 이상적인 아키텍쳐.
진정한 Shared-nothing setup 에서 각 노드는 분리된 호스트에서 실행된다. 이러한 배열은 싱글 호스트나 싱글 노드가 아니면 SOF나 시스템 병목현상이 전체적으로 발생할 수 있다는 데 있다.
In-memory storage
각 데이터 노드에 저장된 모든 데이터는 그 노드의 호스트 컴퓨터의 메모리에 유지된다. 클러스터의 각 데이터 노드를 위해, (데이터 노드의 수로 나뉜 replica의 수 * 데이터베이스 사이즈)만큼의 가용 RAM의 양을 확보해 두어야 한다. 그러니까, 데이터베이스가 1기가의 메모리를 차지하고, 4개의 replica와 8개의 노드로 클러스터를 구성하고자 하면, 각 노드당 최소 500MB의 메모리가 필요하다. 그리고 OS와 다른 어플리케이션 프로그램이 쓰는 메모리가 추가로 필요하다.
Table
관계형 데이터베이스에서는 table은 일반적으로 동일하게 구조화된 레코드의 set을 가리킨다. MySQL 클러스터에서 데이터베이스 테이블은 fragment의 set으로써 데이터 노드에 저장되고, 각 fragment는 추가로 데이터 노드에 복제된다. 같은 fragment를 replicate한 데이터 노드의set이나 fragment의 set을 노드 그룹이라 한다.
Cluster Programs : 명령어들
서버 데몬
- ndbd : 데이터 노드 데몬
- ndb_mgmd : MGM서버 데몬
클라이언트 프로그램
- ndb_mgm : MGM 클라이언트
- ndb_waiter : 클러스터의 모든 노드들의 상태를 확인할 때 사용
- ndb_restore : 백업으로부터 클러스터의 데이터를 복구할 때 사용
'MySQL_Section > cluster' 카테고리의 다른 글
MySQL Cluster 체크포인트 (LCP, GCP) (0) 2014.11.18